These methods extract data from, and attribute new data to,
objects of class "cancor_ord". This is a class introduced in this package
to identify objects returned by cancor_ord(), which wraps
stats::cancor().
Usage
# S3 method for class 'cancor_ord'
as_tbl_ord(x)
# S3 method for class 'cancor_ord'
recover_rows(x)
# S3 method for class 'cancor_ord'
recover_cols(x)
# S3 method for class 'cancor_ord'
recover_inertia(x)
# S3 method for class 'cancor_ord'
recover_coord(x)
# S3 method for class 'cancor_ord'
recover_conference(x)
# S3 method for class 'cancor_ord'
recover_supp_rows(x)
# S3 method for class 'cancor_ord'
recover_supp_cols(x)
# S3 method for class 'cancor_ord'
recover_aug_rows(x)
# S3 method for class 'cancor_ord'
recover_aug_cols(x)
# S3 method for class 'cancor_ord'
recover_aug_coord(x)Value
The recovery generics recover_*() return core model components, distribution of inertia,
supplementary elements, and intrinsic metadata; but they require methods for each model class to
tell them what these components are.
The generic as_tbl_ord() returns its input wrapped in the 'tbl_ord'
class. Its methods determine what model classes it is allowed to wrap. It
then provides 'tbl_ord' methods with access to the recoverers and hence to
the model components.
Details
The canonical coefficients (loadings) are obtained directly from the
underlying singular value decomposition and constitute the active elements.
If canonical scores are returned, then they and the structure correlations
are made available as supplementary elements. ordr takes rows and columns
from the intraset correlations $xstructure and $ystructure, on which no
intertia is conferred; the interset correlations can be obtained by
conferring inertia onto these.
A biplot of the canonical coefficients can be interpreted as approximating
the \(X\)-\(Y\) inner product matrix, inversely weighted by the \(X\)
and \(Y\) variances. The canonical scores and structure coefficients are
available as supplementary points if returned by cancor_ord(). These can be
used to create biplots of the case scores as linear combinations of loadings
(the coefficients, in standard coordinates, overlaid with the scores) or of
intraset and interset correlations with respect to either data set (the
correlations with inertia conferred entirely onto rows or onto columns).
Greenacre (1984) and ter Braak (1990) describe these families, though ter
Braak recommends against the first.
References
Greenacre MJ (1984) Theory and applications of correspondence analysis. London: Academic Press, ISBN 0-12-299050-1. http://www.carme-n.org/?sec=books5
ter Braak CJF (1990) "Interpreting canonical correlation analysis through biplots of structure correlations and weights". Psychometrika 55(3), 519–531. doi:10.1007/BF02294765
See also
Other methods for singular value decomposition-based techniques:
methods-correspondence,
methods-lda,
methods-lra,
methods-mca,
methods-prcomp,
methods-svd
Other models from the stats package:
methods-cmds,
methods-factanal,
methods-kmeans,
methods-lm,
methods-prcomp,
methods-princomp
Examples
# data frame of life-cycle savings across countries
class(LifeCycleSavings)
#> [1] "data.frame"
head(LifeCycleSavings)
#> sr pop15 pop75 dpi ddpi
#> Australia 11.43 29.35 2.87 2329.68 2.87
#> Austria 12.07 23.32 4.41 1507.99 3.93
#> Belgium 13.17 23.80 4.43 2108.47 3.82
#> Bolivia 5.75 41.89 1.67 189.13 0.22
#> Brazil 12.88 42.19 0.83 728.47 4.56
#> Canada 8.79 31.72 2.85 2982.88 2.43
savings_pop <- LifeCycleSavings[, c("pop15", "pop75")]
savings_oec <- LifeCycleSavings[, c("sr", "dpi", "ddpi")]
# canonical correlation analysis with scores and correlations included
savings_cca <- cancor_ord(savings_pop, savings_oec, scores = TRUE)
savings_cca <- augment_ord(as_tbl_ord(savings_cca))
head(get_cols(savings_cca))
#> CanCor1 CanCor2
#> sr 0.0084710221 3.337936e-02
#> dpi 0.0001307398 -7.588232e-05
#> ddpi 0.0041706000 -1.226790e-02
#> Australia 0.1710832312 -2.319485e-02
#> Austria 0.0734979335 4.751571e-02
#> Belgium 0.1608639281 4.001665e-02
head(get_cols(savings_cca, elements = "score"))
#> [,1] [,2]
#> Australia 0.17108323 -0.02319485
#> Austria 0.07349793 0.04751571
#> Belgium 0.16086393 0.04001665
#> Bolivia -0.16793935 -0.01784978
#> Brazil -0.01892735 0.12597599
#> Canada 0.23228391 -0.15548481
get_rows(savings_cca, elements = "structure")
#> [,1] [,2]
#> Australia 0.080362286 0.057700356
#> Austria 0.210217920 -0.124760455
#> Belgium 0.206817659 -0.147353276
#> Bolivia -0.092264868 -0.084150385
#> Brazil -0.135862036 0.123644726
#> Canada 0.057796606 -0.022939696
#> Chile -0.088730206 0.079629867
#> China -0.166969430 0.072566104
#> Colombia -0.165216418 -0.097415107
#> Costa Rica -0.170435473 -0.154462094
#> Denmark 0.176845172 -0.039655162
#> Ecuador -0.155885659 -0.119302333
#> Finland 0.069795922 0.242551458
#> France 0.208472809 -0.263277199
#> Germany 0.158742664 0.151532042
#> Greece 0.125534708 0.132936978
#> Guatamala -0.169084041 -0.026584891
#> Honduras -0.194762607 0.002903451
#> Iceland 0.047939457 -0.166484319
#> India -0.121520306 0.121679633
#> Ireland 0.128086354 -0.351472861
#> Italy 0.154042705 0.073862843
#> Japan 0.054980076 0.392359096
#> Korea -0.127870350 0.119119726
#> Luxembourg 0.190986112 0.107308952
#> Malta 0.031839649 0.046276615
#> Norway 0.150257208 -0.027393904
#> Netherlands 0.141122714 0.126852315
#> New Zealand 0.065255149 -0.138477036
#> Nicaragua -0.143341921 -0.078506548
#> Panama -0.130344329 -0.022294782
#> Paraguay -0.115957618 0.102960459
#> Peru -0.132192367 -0.065939607
#> Philippines -0.158835442 -0.099269419
#> Portugal 0.082942570 0.077033191
#> South Africa 0.028063135 0.117469052
#> South Rhodesia -0.008726758 0.316030295
#> Spain 0.095030764 0.116017873
#> Sweden 0.233670507 -0.090503487
#> Switzerland 0.175588765 0.046093670
#> Turkey -0.134906511 0.014013696
#> Tunisia -0.153181646 -0.117626373
#> United Kingdom 0.213105839 -0.135964931
#> United States 0.103413900 -0.104736278
#> Venezuela -0.170813415 -0.047071960
#> Zambia -0.176876085 0.083089347
#> Jamaica -0.082330658 -0.071878093
#> Uruguay 0.084180403 0.140938007
#> Libya -0.089205403 -0.253474726
#> Malaysia -0.189777503 -0.013574829
#> pop15 -0.982982070 -0.183701522
#> pop75 0.969792868 -0.243929894
get_cols(savings_cca, elements = "structure")
#> [,1] [,2]
#> Australia 0.171083231 -0.023194852
#> Austria 0.073497933 0.047515706
#> Belgium 0.160863928 0.040016653
#> Bolivia -0.167939348 -0.017849776
#> Brazil -0.018927351 0.125975993
#> Canada 0.232283907 -0.155484806
#> Chile -0.139411775 -0.255757534
#> China -0.076484519 0.102650369
#> Colombia -0.151091771 -0.085279284
#> Costa Rica -0.077686953 0.096990052
#> Denmark 0.243481179 0.131320249
#> Ecuador -0.165124499 -0.121601972
#> Finland 0.090745497 0.001878991
#> France 0.173067145 0.005743865
#> Germany 0.199609498 -0.002473117
#> Greece -0.011860145 0.020302710
#> Guatamala -0.172745183 -0.132399004
#> Honduras -0.133371832 0.007517853
#> Iceland 0.021555892 -0.308262763
#> India -0.148002154 0.082042157
#> Ireland 0.015276247 0.062608327
#> Italy 0.075166369 0.135021917
#> Japan 0.135063656 0.315449149
#> Korea -0.157194180 -0.146916393
#> Luxembourg 0.172163609 -0.052380163
#> Malta 0.001285777 0.178757532
#> Norway 0.151317894 -0.064297624
#> Netherlands 0.141333968 0.070216617
#> New Zealand 0.049912057 0.028959254
#> Nicaragua -0.127549491 -0.004188327
#> Panama -0.115291450 -0.131956928
#> Paraguay -0.192048922 -0.154676750
#> Peru -0.079612027 0.192610337
#> Philippines -0.105817455 0.197786992
#> Portugal -0.029527899 0.088439216
#> South Africa -0.053665283 0.102841084
#> South Rhodesia -0.088475821 0.207635702
#> Spain -0.023934583 0.088441591
#> Sweden 0.259747311 -0.251047443
#> Switzerland 0.232635276 0.046153127
#> Turkey -0.135546685 -0.087375693
#> Tunisia -0.181107771 -0.131757959
#> United Kingdom 0.069402362 -0.094341425
#> United States 0.355173128 -0.274111611
#> Venezuela -0.055636386 0.046803247
#> Zambia -0.045547784 0.353236545
#> Jamaica -0.084487974 -0.089413410
#> Uruguay -0.055961815 0.034464260
#> Libya -0.081137138 -0.110362124
#> Malaysia -0.149477671 -0.116250539
#> sr 0.491037858 0.855775971
#> dpi 0.954517196 -0.263726650
#> ddpi 0.047337701 0.140773707
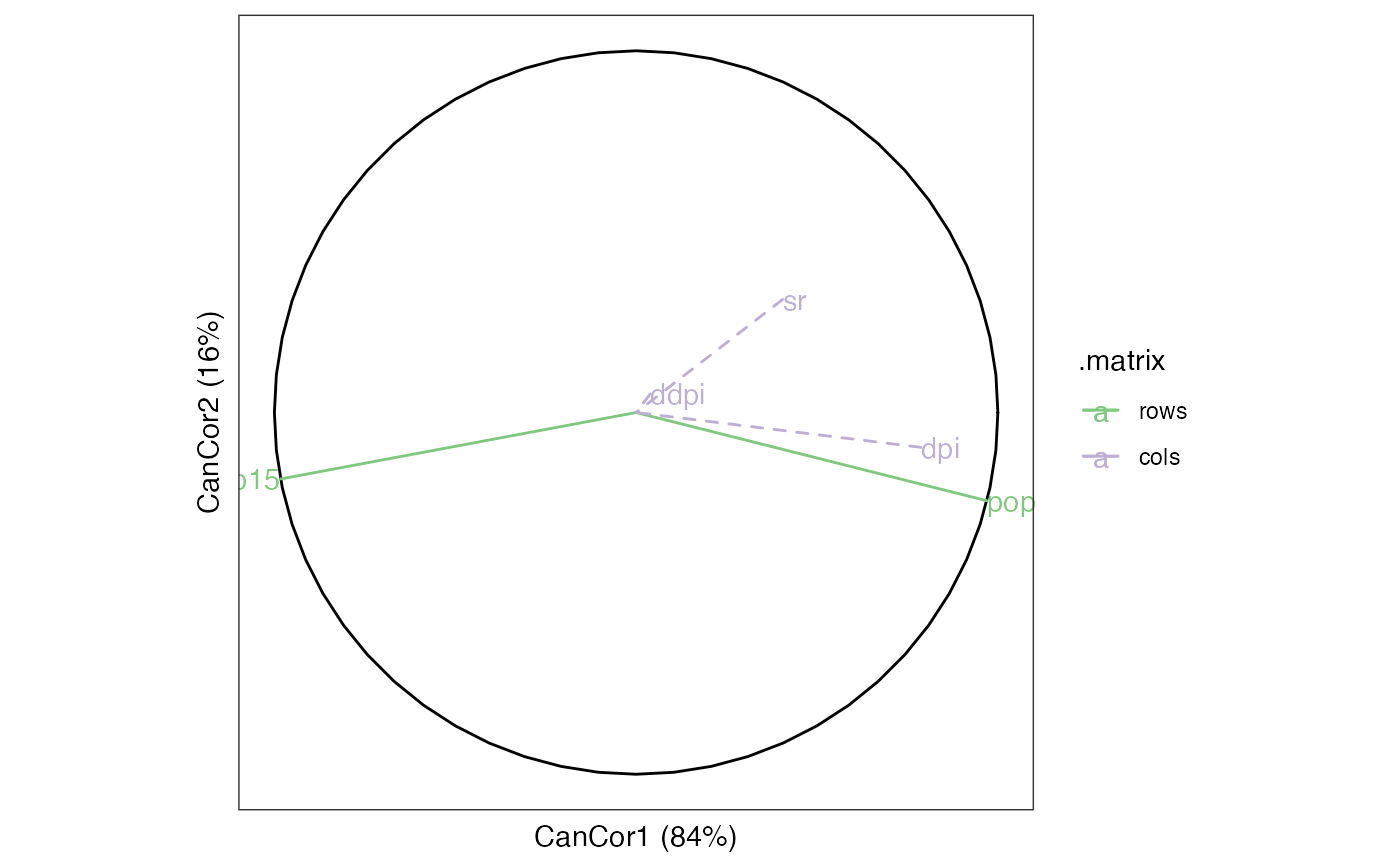
# biplot of interset and intraset correlations with the population data
# NB: `contour = TRUE` is not automatically set as in `geom_density_2d()`
savings_cca %>%
confer_inertia("cols") %>%
ggbiplot(aes(label = name, color = .matrix)) +
theme_bw() + theme_scaffold() +
geom_unit_circle() +
geom_rows_density_2d(elements = "score", color = "grey", contour = TRUE) +
geom_rows_vector(arrow = NULL, elements = "structure") +
geom_cols_vector(arrow = NULL, elements = "structure", linetype = "dashed") +
geom_rows_text(elements = "structure", hjust = "outward") +
geom_cols_text(elements = "structure", hjust = "outward") +
scale_color_brewer(limits = c("rows", "cols"), type = "qual") +
expand_limits(x = c(-1, 1), y = c(-1, 1))
#> Warning: Duplicated aesthetics after name standardisation: contour
#> Warning: The following aesthetics were dropped during statistical transformation: label.
#> ℹ This can happen when ggplot fails to infer the correct grouping structure in
#> the data.
#> ℹ Did you forget to specify a `group` aesthetic or to convert a numerical
#> variable into a factor?
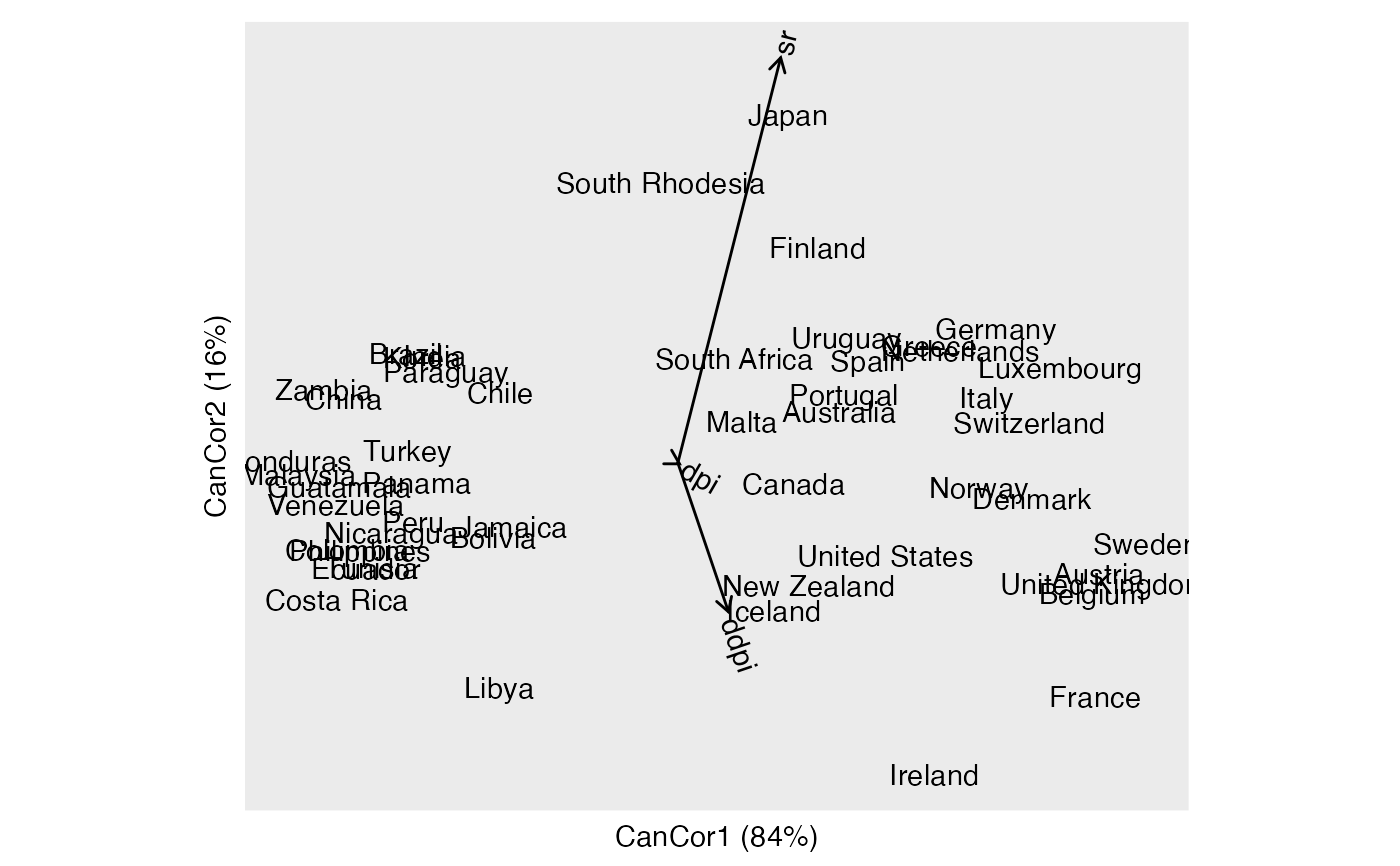
 # situate country scores along financial variables
savings_cca %>%
confer_inertia("rows") %>%
ggbiplot(aes(label = name)) +
theme_scaffold() +
geom_cols_axis(elements = "active") +
geom_rows_text(elements = "score")
# situate country scores along financial variables
savings_cca %>%
confer_inertia("rows") %>%
ggbiplot(aes(label = name)) +
theme_scaffold() +
geom_cols_axis(elements = "active") +
geom_rows_text(elements = "score")